Uma placa de muito interesse para vários dos gamers em PCs, a NVIDIA GeForce GTX 660 completa, junto com a GTX 660Ti, o segmento intermediário da linha de alto desempenho da NVIDIA. Este segmento é importante, pois é onde muitos jogadores encontram a melhor opção para montar seu computador para games.
Assim como a GTX 660Ti, que chegou com preço de US$ 299 (quase 100 dólares abaixo da 670), a GTX 660 chega ao mercado com a virtude de trazer muitas das melhores tecnologias da Nvidia pelo preço competitivo de US$ 229.

Assim como ocorreu com as GTX 680, GTX 670 e GTX 660Ti, a NVIDIA deu um grande salto no número de CUDA cores nesta placa. São 960 contra os 336 que equipam a GTX 560. Outro ganho foi a frequência de operação, que subiu para 980 MHz, contra os 810MHz da geração anterior, lembrando que a placa pode chegar a 1033MHz com o GPU Boost. Na placa da ASUS analisada nesta review, a GTX 660 DirectCU II TOP, o ganho é ainda maior, operando em 1072 MHz e chegando a 1137 Mhz.
Além destas melhorias nas especificações, a placa conta com os demais atributos da nova geração Kepler. É o caso do já mencionado GPU Boost (que turbina dinamicamente os clocks da placa), dos filtros proprietários FXAA (Fast Approximate Anti-Aliasing) e TXAA (Temporal Anti-aliasing), além do recurso adaptive VSync (sincronismo vertical adaptativo) e do 3D Vision Surround.
Juntamente com as tecnologias da própria NVIDIA, a ASUS também traz uma série de melhorias em suas placas da linha DirectCU II TOP, ganhando ainda mais performance através de clocks de operação mais altos, sistema de resfriamento mais eficiente e menos barulhento, e o uso de componentes de qualidade mais alta, buscando dar maior estabilidade ao produto mesmo em condições adversas como o overclock.
No decorrer desta análise, você vai conferir o comportamento da GeForce GTX 660 nos mais diversos testes aos quais foi submetida pela nossa equipe, descobrir o quanto a placa complementa a família GTX, e para quem ela pode ser o produto ideal em termos de custo e benefício.
Sistema de refrigeração DirectCU II eficiente e bastante silencioso;
Excelente acabamento;
Preço bastante competitivo para o segmento;
GPU e memória overclockadas de fábrica;
Desepenho próximo ao da GTX 660 Ti de referência em diversas situações;
Necessidade de apenas um conector de energia de 6 pinos;
Placa funciona com temperatura “baixa”, mesmo overclockada.
TDP relativamente elevado se comparado com a GTX 660 Ti
Com a Fermi, os engenheiros da NVIDIA empregaram todo o seu conhecimento adquirido ao longo das duas últimas gerações, bem como todos os aplicativos, e desenvolveram uma abordagem totalmente nova de design para criar a primeira GPU computacional do mundo. A arquitetura era baseada em pipelines de geometria paralela otimizados para o Tessellation e para o mapeamento de deslocamento, bem como para uma nova arquitetura computacional que oferecia mais velocidade na troca de contexto e aprimoramento no desempenho para operações atômicas.
Já a Kepler, embora construída a partir dos alicerces da Fermi, parece dar um passo adiante na evolução dos chips gráficos da NVIDIA, ao focar na otimização e eficiência de recursos.
A nova geração de GPUs é composta de inúmeros blocos de hardware distintos, cada um especializado em tarefas específicas. Entretanto, o GPC (Graphic Processing Cluster ou Feixe de Processamento Gráfico) continua a ser o bloco de hardware de alto nível dominante na arquitetura Kepler, com recursos dedicados para a computação geral, rasterização, sombreamento e texturização. Em outras palavras, quase todas as funções de processamento gráfico de um núcleo da GPU estão contidas no GPC.

Conforme pode ser visto acima na estrutura de processamento da Kepler (chip GK104), há um grande bloco chamado pela NVIDIA de “Gigathread Engine”, composto de quatro GPCs, quatro controladores de memória, partições de rasterizadores (ROPs) e memória cache L2. Vale ressaltar que cada Feixe de Processamento Gráfico, que são na realidade grandes unidades de processamento e se comportam como mini GPUs independentes, possui duas unidades da nova geração de Streaming Multiprocessors, chamados agora pela companhia de SMX (até então a companhia havia batizado os multiprocessadores de Streaming de SM). Diferentemente das duas gerações passadas (GF10x e GF11x), em que cada SM continha 32 CUDA Cores (ou Shader Processors), os SMX da geração Kepler possuem nada menos do que impressionantes 192 Shaders! Dessa forma, a NVIDIA chegou ao número “mágico” de 1536 CUDA Cores (4 GPCs x 2 SMXs x 192 Shader Processors) no chip GK104 da GTX 680.
Como não poderia deixar de ser, a tática de desativar um(alguns) conjunto(s) de recurso(s) se repete com a geração Kepler. Assim, ao invés de 8 unidades de SMX, a GK104 presente nas GTX 670 e GTX 660 Ti possui 7 unidades. Com isso, a quantidade total de CUDA Cores cai de 1536 para 1344 (8 SMXs x 192 Shader Processors).
Seguindo esta linha de raciocínio, alguém mais desavisado poderia pensar: “Não seria mais simples, então, a NVIDIA simplesmente ir reduzindo a quantidade de unidades SMX no GK104, para compor as GeForces menos potentes?!” Bem, em termos de “simplicidade” de engenharia, sem dúvidas – pois ao invés de se projetar e construir vários chips, bastaria apenas um. Entretanto, em termos comerciais, tal atitude seria totalmente inviável. Não se esqueçam que a construção de um chip do porte do GK104 é algo oneroso. Trocando em “miúdos”, hipoteticamente falando, seria insano colocar um chip com custo de produção – digamos – de US$ 149 (fora os custos dos demais componentes e custos indiretos, como o de comercialização/marketing), em uma VGA que tem valor final para o consumidor de US$ 249.
Assim, nada mais justo e natural para a NVIDIA do que empregar um chip “mais simples” e com custo de produção menor, em uma GeForce voltada para um segmento “mais palpável” da população. Eis que entra em cena, então, o GK106.

( Bloco de Diagrama do chip GK106)
Como pode ser constatado na imagem acima, o GK106 possui uma configuração inusitada em termos de Graphic Processing Cluster. Ao invés de contar com 3 GPCs, o chip possui “2,5” Feixes de Processamento Gráfico, resultando assim em 5 unidades de SMX, ao invés de 6. Assim, a GTX 660 possui um total de 960 CUDA Cores (5 SMX x 192 Shaders Processors).
Isto explica, finalmente, o motivo da GTX 660Ti ser baseada no GK104 e não no GK106, uma vez que 960 CUDA Cores é uma quantidade muito “reduzida” para as pretensões da variante Titatium. Se por um lado, a ausência de uma unidade SMX a mais no chip acarretou na impossibilidade da GTX 660 ser mais robusta, com 1152 CUDA Cores, por outro, “poupou” alguns importantes milímetros na área do die da GPU.
Outra mudança visível na comparação entre as arquiteturas da Fermi e Kepler está na quantidade máxima de controladores de memória. Ao invés de seis blocos de 64 bits, há “apenas” quatro, totalizando assim um bus de 256 bits (4 blocos x 64 bits) para a GK104 (GTX 680/670) contra 384 bits das GF100 e GF110. Assim como a variante Ti, a GTX 660 possui apenas 3 blocos, totalizando em um barramento de memória (bus) de 192 bits.
Os mais atentos devem estar pensando: “Como conseguir 2GB de memória, ao invés de 1,5GB com um bus de 192 bits, já que, via de regra, cada bloco de 64 bits está associado a módulos de 512MB”? A resposta é que a GTX 660 (assim como algumas GPUs) possuem controladoras de memórias que funcionam com uma configuração anômala em termos de densidade. A controladora lógica de memória da GTX 660 é composta por 8 módulos, assim divididos:
Controladora 1 – 4 módulos: 128M x 16 GDDR5 (1GB, modo 16 bits)
Controladora 2 – 2 módulos: 64M x 32 GDDR5 (512MB, modo 32bits)
Controladora 3 – 2 módulos: 64M x 32 GDDR5 (512MB, modo 32bits)
As 3 controladoras segmentam a memória em fragmentos iguais de 512MB para criar uma área de armazenamento de dados de 1,5GB com interface de 192 bits. Contudo, os 512MB restantes são acessados em uma transação de memória adicional, pela controladora 1 com largura de 64 bits. Assim, a GPU tem acesso aos 2GB de VRAM, com um mínimo de latência.
Em relação à quantidade de unidades de rasterização, o GK106 possui um total de 24 ROPs – mesma quantidade do GK104 presente na GTX 660 Ti – contra 32 ROPs do GK104 das GeForces GTX 680/670. Essa diferenciação se dá em virtude da redução no número de blocos rasterizadores. Enquanto que o chip da GTX 660 tem 3 blocos de 8 ROPs, o GK104 tem 4 com 8 rasterizadores cada (à exceção do chip presente na GTX 660 Ti, que tem 3). A título informativo, a linha Fermi (GF100/GF110) tem um total de 6 blocos, totalizando assim 48 ROPs.
Quanto às unidades de texturização, cada SMX é composto por 16 TMUs, quatro vezes mais TMUs em relação ao Streaming Multiprocessor da geração Fermi. Com um total de 8 SMXs (4 GPCs x 2 SMXs), o GK104 tem, portanto, um total de 128 unidades de texturização (112 no GK104 da GTX 660 Ti – 7 SMXs x 16 TMUs), contra 64 da GF110 (16 SM x 4 TMUs). Pelo fato de ter 5 unidades SMX, o GK106 possui 80 unidades de texturização (5 SMXs x 16 TMUs).
As principais unidades de hardware responsáveis pelo processamento das GeForces da geração Kepler estão inseridas dentro da estrutura do SMX, como é o caso dos CUDA Cores, que lidam, entre outros pontos, com o processamento dos vértices, pixels e da geometria, bem como os cálculos computacionais e de física.
Além disso, é aí que se encontram as unidades de texturização que lidam com a filtragem das texturas, com o carregamento/armazenamento das unidades de busca (units fetch) e pelo salvamento dos dados na memória.
 (Digrama do SMX – Geração Kepler)
(Digrama do SMX – Geração Kepler) Além disso, há ainda as unidades Warp Scheduler e Master Dispatch que se alimentam de arquivos de registros (Register Files) imensos (65.536 entradas de 32-bits – o arquivo de registro pode aceitar formatos diferentes ou seja, 8-bit, 16-bit, etc). O cluster SMX possui ainda 16 TMUs, cache de textura e o mais importante de tudo: PolyMorph Engine 2.0.
As unidades de Polymorph Engine foram introduzidas na Fermi para lidar com uma enorme carga de trabalho advinda das novas tecnologias, como é o caso da API gráfica DirectX 11. Talvez, a principal delas seja a badalada técnica de aprimoramento da qualidade das imagens, conhecida como Tessellation (Tess), que aumenta de forma quase exponencial a quantidade de triângulos em uma cena, exigindo assim o máximo da GPU.
Com a geração Kepler, a NVIDIA aprimorou o seu motor de processamento, ao introduzir a Polymorph Engine 2.0 que, de acordo com a companhia, possibilitou o dobro de desempenho do processamento primitivo e de Tessellation por SMX, em relação à Fermi.
A PolyMorph Engine 2.0 lida com os buscadores de vértices, com o Tessellation, transformador viewport, configurador de atributo e saída de streaming.
Finalmente, as Unidades de Função Especial, mais conhecidas pela sigla em inglês SFU (Special Function Units) controlam instruções transcendentais e de interpolação gráfica.
Abaixo, um resumo das principais especificações da GeForce GTX 660.
• Nova litografia em 28 nm;
• Área do die (estimado): 221mm2;
• Frequência de operação das texturas e ROPs (GPU): 980MHz (base clock) / 1033Mhz (boost clock);
• 960 CUDA Cores/shader processors;
• Frequência de operação das memórias: 6008MHz (GDDR5);
• Quantidade de memória: 2GB;
• Interface de memória: 192bits;
• TDP: máximo de 140 watts;
• Limiar térmico da GPU em 98° C;
• Suporte às tecnologias: CUDA, DirectX 11.1, GeForce 3D Vision, NVIDIA 3D Vision Surround, Filtros FXAA/TXAA, GPU Boost, Adaptive VSync, NVIDIA PhysX, PureVideo HD Technology, HDMI 1.4a, OpenGL 4.2, OpenCL, DirectCompute, Windows 7.
E ainda:
• Nova Geração do Streaming Multiprocessor (SMX);
• 192 CUDA cores por SMX, 6x mais que a GF110 (GTX 580/GTX 570);
• 5 PolyMorph Engines 2.0;

Assim como as suas “irmãs maiores”, a GTX 660 chama a atenção pela imensa quantidade de CUDA Cores (Stream Processors, ou ainda Shaders Cores) em relação às GeForces da geração Fermi (GTX 500/400).
A GTX 660 conta com quase 3 vezes mais processadores gráficos que a GTX 560, ou seja, 960 CUDA Cores contra 336! Em relação à sua “irmã maior”, a diferença é de 40% em favor da GTX 660 Ti, graças aos seus 1344 CUDA Cores.
Conforme esclarecido no tópico anterior, houve mudanças em sua arquitetura interna. Portanto, não é correto fazer uma comparação de performance levando-se em conta apenas o número de processadores gráficos. Ou seja, uma GeForce Kepler com 3 vezes mais CUDA Cores que uma GeForce Fermi, não terá necessariamente desempenho 200% maior. Ainda assim, as mudanças na arquitetura mostraram-se bem eficientes, principalmente no quesito performance por watt gasto.
Outras gratas evoluções dizem respeito às frequências de operação da GPU e memória. Enquanto que a GTX 560 tem core clock em 810Mhz e VRAM em 4008Mhz, a NVIDIA elevou os patamares da GTX 660 respectivamente em 21% e 50%, isto é, para 980Mhz e 6008Mhz. E isso para o modelo padrão, pois há várias VGAs especiais com clocks ainda maiores, como é o caso da ASUS GTX 660 DirectCU II com GPU em 1072Mhz e memória em 6108Mhz. O clock da GPU é, inclusive, 7% maior que o da variante Ti, provavelmente para compensar a substancial diferença na quantidade de CUDA Cores. Já as VRAMs de ambas trabalham na mesma velocidade.
Ainda no campo das “compensações”, embora a GTX 560 tenha memória 33% mais lenta que a GTX 660, seu barramento é de 256 bits, contra 192 bits da nova GeForce. Ainda assim, a combinação entre bus e clock da VRAM resulta em uma largura de banda de memória de 144,2 GB/s para a GTX 660 (idêntica para a variante Ti), contra 128,3 GB/s para a sua “irmã mais velha”.
Em virtude do refinamento no processo de fabricação da GPU (de 40nm para 28nm), a GTX 660 (GK106) tem área de die do chip 30% menor que a GTX 560 (GF114) – 221mm2 contra 318mm2. Trata-se de uma grata evolução, uma vez que a diferença de transistores entre os chips é de quase 600 milhões (2,54 bilhões para a GTX 660, contra 1,95 bilhão para a GTX 560). Além disso, a dissipação térmica máxima entre as duas placas reduziu em 10W, de 150W na GTX 560 para 140W na GTX 660.
Vale mencionar que, para suprir os 140W, a companhia disponibilizou um conector de energia de seis pinos, capaz de fornecer 75W adicionais aos 75W do PCI Express. Com esta configuração, elimina-se a necessidade da utilização de adaptadores (o que não é recomendável), além de aumentar (e muito) o espectro de fontes (PSUs) compatíveis com a placa. Assim, uma fonte real de 400W é mais do que suficiente para suprir as necessidades de todos os componentes do PC.

Conforme já mencionado no decorrer desta análise, a nova geração Kepler trouxe gratas surpresas para os usuários. Algumas exclusivas, como é o caso dos novos filtros FXAA e TXAA, do GPU Boost, Adptive VSync e 3D Vision Surround com apenas uma VGA. Outras são comuns às demais placas de nova geração, como é o caso do suporte ao DirectX 11.1 e do PCI Express 3.0. Detalharemos a seguir as novidades.
DirectX 11.1
Apesar do suporte à mais recente API Gráfica da Microsoft ter sempre sido motivo de destaque no marketing das companhias, ao que parece, a NVIDIA não está tão empolgada com tal fato. Tanto que, apesar de a arquitetura Kepler suportar o DirectX 11.1, John Danskin, vice-presidente de arquitetura de GPU da NVIDIA, soltou a seguinte frase durante o NVIDIA Editor's Day em São Francisco (evento super seleto, fechado a um restrito grupo de jornalistas de várias partes do mundo – e coberto pelo Adrenaline): “Sim, [a GeForce GTX 680] será compatível com DirectX 11.1, mas… quem se importa?”

Provavelmente o que o executivo quis dizer foi que a atualização da API Gráfica da Microsoft não trará tantas melhorias gráficas; e mais ainda: deverá demorar até que o DX11.1 seja adotado amplamente pelos games – assim como o próprio DX11. Até que isso ocorra, é provável que as GeForces da série 700 ou mesmo 800 já tenha sido lançadas.
Outro ponto é que, até o Windows 8 chegar, tal recurso ficará apenas no papel. Ainda assim, as principais novidades do DX11.1 serão:
• Rasterização independente de objeto;
• Interoperabilidade flexível entre computação gráfica e vídeo;
• Suporte nativo ao Stereo 3D.
PCIe Gen 3
Na medida em que novas gerações de placas chegavam ao mercado, foi gerado um temor nos analistas de que o padrão de interface de comunicação PCI Express chegaria a um ponto em que não conseguiria dar mais vazão ao fluxo de dados com a intensidade necessária, criando assim um verdadeiro gargalo para o desempenho da VGA.
Este temor, contudo, se diluiu, com o recente anúncio da geração 3 do PCIe, que dobrou a taxa de transferência em relação ao PCIe Gen 2, garantindo tranquilidade para as futuras placas 3D.
Com o novo patamar de desempenho advindo da geração Kepler, a NVIDIA garantiu o suporte ao PCI Express 3.0 nas GeForces série 600, encerrando qualquer tipo de temor em relação a gargalo de desempenho.
Com o PCIe Gen 3, a largura de banda saltou de 16GB/s para 32GB/. Já nas placas acessórias instaladas, o ganho saiu de 500MB/s para 1GB/s por pista/linha. Assim, os dispositivos que utilizam a configuração x16 podem utilizar de 16GB/s, ou 128Gbps. Vale ressaltar, contudo, que para se beneficiar do PCI Express 3.0 o usuário deverá ter um sistema totalmente preparado e compatível com tal recurso. Assim, além de uma VGA PCIe Gen 3.0, tanto a placa-mãe quanto o processador deverão suportar a novidade.
GPU Boost

Exclusivo das GeForces, trata-se da tecnologia combinada de harware com software de ajuste dinâmico nos clocks.
Semelhante ao Turbo Boost da Intel e ao TurboCore da AMD, o GPU Boost tem como objetivo disponibilizar a quantidade de megahertz necessária para o bom funcionamento das tarefas, a depender, claro, de certas condições, como consumo de energia e temperatura da GPU.
Com a Kepler, há agora os conceitos de clocks base (base clock) e clock de impulso (boost clock). Dessa forma, a GTX 660 opera por padrão em 980Mhz, podendo ir a 1033Mhz (1072Mhz/1137Mhz na ASUS GeForce GTX 660 DirectCU II TOP) (overclock de 5,4% na GTX 660 e 6,1% na placa da Asus) quando for preciso um maior poder de processamento (como a renderização de gráficos complexos), desde, claro, que haja condições para isso (TDP e temperatura abaixo do máximo permitido). Em outras palavras, a tecnologia utiliza a diferença entre o consumo atual (varia de acordo com o software executado) e o TDP máximo da placa, para alavancar o clock base e aumentar a performance, chegando assim ao patamar que a NVIDIA denominou de “boost clock”.

(Algoritmo de execução do GPU Boost)
Em alguns casos, esse upgrade dinâmico pode superar em 10% o clock base da GeForce, ou seja, chegar a casa do gigahertz, desde, novamente, que haja condições para isso. O mais bacana é que, se você for um overclocker por natureza e quiser elevar ainda mais o desempenho via overclock tradicional, o GPU Boost continuará funcionando mesmo com a placa overclockada, variando os clocks para cima e para baixo da mesma forma que em VGAs com clocks default.

(Cada jogo utiliza uma quantidade específica de energia da VGA.
O GPU Boost monitora o consumo de energia em tempo real e aumenta o clock da GPU quando há condições disponíveis.)
Entretanto, caso o usuário esteja realizando tarefas triviais, como, por exemplo, surfando na web, ou utilizando uma suíte de escritório, o GPU Boost reduz automaticamente a frequência de operação do chip gráfico para economizar energia. Além de dar uma “ajudinha” no bolso do usuário no final do mês com a conta de energia, a tecnologia é particularmente interessante para o mundo dos portáteis, onde qualquer otimização na autonomia da bateria é bem-vinda.
FXAA
Embora não seja um filtro de Anti-Aliasing (antisserrilhado) inédito, a NVIDIA aprimorou o FXAA (Fast Approximate Anti-Aliasing) na nova geração Kepler.
Semelhante ao MLAA (Morphological Anti-Aliasing, ou Antisserrilhamento Morfológico) empregado pela AMD nas novas Radeons, o FXAA é uma técnica de pós-processamento, isto é, que aplica o filtro de anti-aliasing na imagem após esta ter sido gerada pela GPU. Isso é bastante vantajoso, haja vista que alivia a carga de trabalho da unidade de processamento gráfico. Vale destacar que o FXAA é aplicado junto com outras técnicas de pós-processamento, como é o caso do motion blur e do bloom.
Com a chegada da Kepler, a NVIDIA passou a adotar o FXAA via driver (geração R300), possibilitando a utilização do filtro em centenas de jogos. Outro destaque do Fast Approximate Anti-Aliasing sobre o Morphological Anti-Aliasing está no ganho de desempenho, chegando a ser 60% mais veloz que o MSAA em 4X.
Um fato que chamou bastante a atenção da comunidade foi a apresentação do Samaritan Demo (demonstração de um vídeo da Epic que ressalta o poderio gráfico do DirectX da Unreal Engine) na Game Devolpers Conference – GDC 2011. Na ocasião, a Epic necessitou de três GeForces GTX 580 para rodar o demo a contento. Passado um ano, ou seja, na GDC 2012, a Epic fez uma nova apresentação do Samaritan Demo. Contudo, para a surpresa de todos, foi necessário apenas uma GeForce GTX 680 e a utilização do FXAA para “dar conta do recado”.
Para ver um comparativo mais apurado dos benefícios do filtro, clique aqui.
TXAA
Considerado pela NVIDIA como a próxima geração de filtros de antisserilhamento (responsável pela geração do próximo nível em termos de qualidade de imagem), o TXAA (Temporal Anti-aliasing) promete disponibilizar muito mais qualidade e performance se comparado com o MSAA.
Segundo a companhia, o antisserilhamento temporal foi criado com o objeto de explorar toda a capacidade de processamento de texturas da geração Kepler (mais especificamente nas placas baseadas no chip gráfico GK104, ou seja, nas GTX 680/670/660).
O TXAA é um misto de anti-aliasing de hardware com filme GC estilo AA, e para o caso do filtro em 2X, um componente temporal opcional é empregado, para melhorar a qualidade da imagem.
O filtro de Temporal Anti-aliasing está disponível em dois modos: TXAA1 e TXAA2. De acordo com a NVIDIA, o TXAA1 oferece uma qualidade gráfica superior ao MSAA em 8X, com gasto de processamento semelhante ao MSAA em 2X. Já o TXAA2 permite uma qualidade das imagens superior ao TXAA1, com performance comparável ao MSAA em 4X.
Inicialmente o filtro antisserilhamento temporal será implementado diretamente na engine de alguns dos principais jogos da futura geração. Até o momento, a Epic Games, com a sua badalada Unreal Engine Technology 4, e a Crytek, são dois dos principais estúdios que já estão desenvolvendo games com o novo filtro da NVIDIA.
Adptive VSync

O sincronismo vertical – V-Sync foi projetado para lidar com os chamados artefatos fora de sincronismo ou artefatos trepidantes (tearing artifacts ), que podem ocorrer quando a quantidade de FPS é bem superior à taxa de atualização (refresh rate) do monitor, e que além de causarem um desconforto visual, prejudicam a jogabilidade do usuário. Embora seja raro, é possível ainda que o fenômeno aconteça na situação inversa ao mencionado acima, ou seja, quando os FPS são bem menores que a taxa de atualização da tela.
(Tearing artifacts)
Apesar de criado com o intuito de acabar (ou amenizar) com os tearing artifacts, o V-Sync gerou outro problema: a perda de frames (stuttering), também conhecido como “lag”. Isso ocorre quando os FPS caem para menos de 60 quadros por segundo, ocasionando a redução do V-Sync para 30Hz (e demais quocientes de 60, como 20Hz ou 15Hz).

(Problema de sincronismo vertical – VSync)
Como forma de enfrentar esse desafio, os engenheiros de software da NVIDIA criaram o Adptive V-Sync. Presente na geração de drivers R300 da companhia, a tecnologia dinamicamente liga e desliga o sincronismo vertical, de forma a gerar FPS mais regulares e cadenciados, o que minimiza os lags nos games e previne a má sincronização das imagens.
Mais especificamente, quando a taxa de quadros por segundo cai para menos de 60 FPS, o Adptive V-Sync entra em cena e desliga o sincronismo vertical, possibilitando que os frame rates funcionem em sua taxa natural, o que reduz as chances de ocorrer lag. Quando os FPS voltam para 60 quadros por segundo, o Adptive V-Sync atua novamente ao ligar o sincronismo vertical, reduzindo a possibilidade de ocorrerem artefatos fora de sincronismo.

(Adptive V-Sync em funcionamento)
NVENC
A NVIDIA introduziu em todas das VGAs da linha Kepler o NVENC, novo vídeo encoder para o padrão H.264.
Antes do NVENC, as GeForces utilizavam o Badaboom (mais detalhes na próxima seção), que utiliza do poder dos CUDA Cores para a conversão de diferentes formatos de streaming multimídia. Se, por um lado, esse recurso tem a grande vantagem de desafogar o processador e acelerar o processo, por outro, tem o ponto fraco de aumentar o consumo de energia da placa durante a conversão.
Para resolver essa questão, a NVIDIA criou o NVENC, que utiliza um circuito especializado para o “encodamento” H.264. Vale destacar que tal circuito é quase quatro vezes mais veloz que o encoder via CUDA Cores, além de consumir consideravelmente menos energia que o Badaboom.
O NVENC é capaz de lidar com as seguintes situações:
– Encodar vídeos em fullHD (1080p) com velocidade até oito vezes maior que em tempo real. De acordo com a companhia, em modo de alta performance, o NVENC é capaz de encodar um vídeo de 16 minutos em 1080p @ 30 FPS em apenas dois minutos;
– Suporte ao padrão H.264 nos níveis de profile 4.1 Base, Main e High (mesmo que o padrão Blu-Ray);
– Suporte ao MVC (Multiview Video Coding) para vídeos estereoscópicos – extensão do H.264 para o padrão Blu-Ray 3D;
– “Encodamento” para resolução de até 4096×4096 pixels.
É bom que se diga que, além da transcodificação, o NVENC é útil para edição de vídeos, telas do tipo wireless (sem fio) e aplicações de vídeo conferência.
CUDA
 Trata-se da abreviação para Compute Unified Device Architecture (em tradução livre: Arquitetura de Dispositivo Unificado de Computação). Em outras palavras, CUDA é o nome dado pela NVIDIA para designar a arquitetura de computação paralela mais conhecida como GPGPU (general-purpose computing on graphics processing units).
Trata-se da abreviação para Compute Unified Device Architecture (em tradução livre: Arquitetura de Dispositivo Unificado de Computação). Em outras palavras, CUDA é o nome dado pela NVIDIA para designar a arquitetura de computação paralela mais conhecida como GPGPU (general-purpose computing on graphics processing units).
Sem maiores complicações ou termos técnicos, trata-se da tecnologia na qual se utiliza uma GPU (chip gráfico) para realizar uma tarefa comumente executada por um processador (CPU). Isso só é possível graças à adição de estágios programáveis e da aritmética de maior precisão contidas nos canais de processamento da GPU, que permite que os desenvolvedores de programas utilizem o processamento de fluxo de dados para dados não gráficos.
Apresentada inicialmente em 2007, a tecnologia CUDA está presente em uma vasta gama de chips da NVIDIA, tais como nas GPUs de classe científica Tesla, nas profissionais Quadro, além, é claro, das GeForces desde a geração G8x.
De acordo com vários experts no assunto, a grande vantagem de utilizar uma GPU ao invés de uma CPU para realizar tarefas do cotidiano está na arquitetura por trás do chip gráfico, massivamente focado na computação paralela, graças à imensa quantidade de cores/núcleos. Eles são, portanto, capazes de rodar milhares de threads simultaneamente. Dessa forma, aplicações voltadas para a biologia, física, simulações, criptografia, entre outras, terão um benefício muito maior com a tecnologia GPGPU/CUDA.
No campo dos games, a renderização dos gráficos torna-se muito mais eficiente com a Compute Unified Device Architecture, como por exemplo, nos cálculos dos efeitos da física (como é o caso da fumaça, fogo, fluidos…)
Atualmente, é o processo de GPGPU mais difundido no mercado, com mais de 100 milhões de placas compatíveis.
PhysX
 Embora seja uma das grandes “vedetes” dos games modernos, a tecnologia de processamento da física é uma tecnologia que já vem de alguns anos.
Embora seja uma das grandes “vedetes” dos games modernos, a tecnologia de processamento da física é uma tecnologia que já vem de alguns anos.
Lançada inicialmente em 2005 pela então AGEIA, com a sua famigerada PPU (Physics Processing Unit – um tipo de chip exclusivo para o processamento da física), a iniciativa nunca chegou a decolar em virtude de seu alto custo para a época, apesar de toda a promessa por trás da tecnologia.
Contudo, a NVIDIA enxergou na PPU da AGEIA uma imensa oportunidade pela frente. Tanto foi que, em 2008, anunciou para o mercado a compra da companhia, bem como de seu bem mais precioso: a tecnologia PhysX. Assim, a NVIDIA passou a incorporar os benefícios da PPU dentro de suas GPUs.
Muito bem, mas o que vem a ser exatamente o tal cálculo da física presente no PhysX? Trata-se da técnica na qual o chip gráfico realiza uma série de tarefas específicas em um game, tornando-o mais realista para o jogador ao adicionar ambientes físicos vibrantes, de imersão total.
A física é o próximo passo na evolução dos jogos. Diz respeito à forma como os objetos se movimentam, interagem e reagem ao ambiente que os cerca. Em muitos dos jogos atuais, sem física, os objetos não parecem se mover da forma desejada ou esperada na vida real. Hoje em dia, a maior parte da ação se limita a animações pré-fabricadas, que são acionadas por eventos do próprio jogo, como um tiro que acerta a parede. Até as armas mais pesadas produzem pouco mais que uma pequena marca nas paredes mais finas, e todos os inimigos atingidos caem da mesma forma já programada. Para os praticantes, os jogos são bons, mas falta o realismo necessário para produzir a verdadeira sensação de imersão.
Em conjunto com as GPUs GeForce habilitadas para a CUDA, o PhysX oferece a potência computacional necessária para produzir a física avançada e realista nos jogos de próxima geração, deixando para trás os efeitos de animação pré-fabricados.
É através do cálculo da física que, por exemplo, uma explosão parece mais real para o usuário, uma vez que se pode gerar um verdadeiro “efeito dominó” por trás desse evento. Assim, é possível adicionar uma série de elementos para a cena, como é o caso de estilhaços, e não mais apenas o fogo e a fumaça.
O PhysX é responsável, entre outras funções, por processar as seguintes tarefas em um game:
• Explosões com efeitos de poeira e destroços;
• Personagens com geometrias complexas e articuladas para permitir movimentação e interação mais realistas;
• Novos e incríveis efeitos nos efeitos dos disparos de armas;
• Tecidos que se enrugam e rasgam naturalmente;
• Fumaça e névoa formadas em torno de objetos em movimento.

(Vídeo de Batman Arkham Asylum, que compara o game com e sem o PhysX)
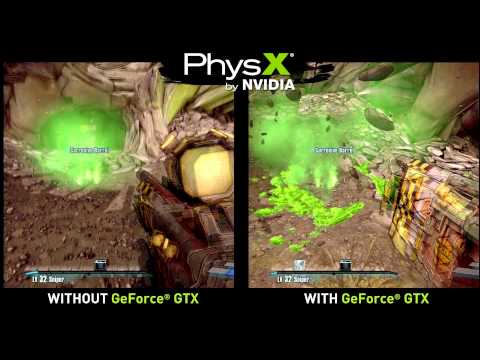
(Vídeo de Borderlans 2 mostrando efeitos do PhysX em uma GTX 660 Ti)
3D Vision Surround
 Lançado no início de 2009 durante a Consumer Electronic Show (CES) em Las Vegas, Estados Unidos, o 3D Vision foi de início motivo de certa desconfiança por parte da comunidade. A razão nada teve a ver com a tecnologia em si (muito boa por sinal), mas sim por experiências nada bem sucedidas de outras empresas no passado.
Lançado no início de 2009 durante a Consumer Electronic Show (CES) em Las Vegas, Estados Unidos, o 3D Vision foi de início motivo de certa desconfiança por parte da comunidade. A razão nada teve a ver com a tecnologia em si (muito boa por sinal), mas sim por experiências nada bem sucedidas de outras empresas no passado.
Antes do 3D Vision, basicamente a sensação de imagens tridimensionais era (e na maioria dos casos ainda é) feita por óculos anaglíficos (famosos por suas lentes na cor azul e vermelha), ou por lentes mais elaboradas com LCD (aos moldes dos óculos presentes no Master System), mas que pecavam por suas limitações técnicas. Era esse o caso das televisões e monitores de CRT (tubo) que causavam dores de cabeça com o uso prolongado ou de LCDs com baixa taxa de atualização (refresh rate).
Contudo, a NVIDIA lançou um produto sem impedimentos técnicos, aproveitando-se da nova geração das telas de cristal líquido, com nada mais nada menos do que 120Hz (60Hz para cada olho).
Não basta apenas comprar o kit e um monitor especial e sair usufruindo da tecnologia. É preciso que o jogo tenha suporte a imagens em três dimensões. Dessa forma, o driver ForceWare reconhece a compatibilidade e entra em ação, acionando o 3D Vision e alternando os frames para o lado esquerdo e direito do óculos a cada atualização de imagem (técnica conhecida como multiplexação sequencial de tempo). Utilizando-se dos dados contidos na engine Z-buffer, o programa é capaz de criar uma representação 3D do game, ao invés de apenas duplicar e compensar a imagem para criar o efeito, como faz, por exemplo, o monitor Triton da Zalman, dinamicamente alternando a profundidade e então a distância dos objetos no game.
Foi uma ação extremamente ambiciosa e ousada da NVIDIA, já que ela teve que contar com o apoio das produtoras para disponibilizar cada vez mais títulos compatíveis com a tecnologia. Porém, para a felicidade da gigante das GPUs, a companhia dispõe do programa “The Way It's Meant To Be Played”, em que atua em conjunto com diversos estúdios dando o suporte para o desenvolvimento de novos jogos.
Vale ressaltar que a tecnologia não está limitada apenas aos games. É possível, por exemplo, desfrutar de imagens e vídeos em três dimensões.
Utilizado em conjunto com as GPUs GeForce, o 3D Vision consiste nos seguintes componentes:
• Óculos Sem Fio 3D Estereoscópico Ativo – Projetado com lentes especiais, oferece o dobro de resolução por olho e ângulo de visão superior, em comparação com os óculos passivos. Parecidos com os óculos de sol, são uma alternativa aos tradicionais óculos 3D de papel e plástico.
• Emissor Infravermelho de alta potência (porta USB) – Transmite dados diretamente para os óculos 3D, a uma distância de até seis metros, além de possuir um controle de ajuste em tempo real.
• Monitores Ultra-Flexíveis – Projetado para os monitores LCD de 120Hz, o 3D Vision produz imagens 3D estereoscópicas nítidas em soluções de todos os tipos.
• Softwares de Compatibilidade – Softwares da NVIDIA convertem automaticamente mais de 300 jogos para o formato 3D Stereo, sem a necessidade de patches ou atualizações. O 3D Vision também é a única solução 3D a suportar as tecnologias SLI e PhysX.
• Visualizador 3D – Inclui também um visualizador 3D Vision gratuito que permite a captura de screenshots e sua posterior visualização em 3D. Também é possível importar fotos e vídeos 3D de diversas outras fontes, como galerias de fotos da Internet.
(Kris Rey da NVIDIA jogando Skyrim em 3 monitores,
enquanto navega no portal GeForce.com para acessar o guia de otimização do jogo para a VGA)
O passo seguinte no avanço da tecnologia 3D foi o lançamento do 3D Vision Surround (imagem acima), que possibilitou utilizar até três monitores simultâneos, formando assim uma ampla área de visualização em três dimensões.
Com a chegada da linha Kepler (mais especificamente da GeForce GTX 680), a NVIDIA aprimora ainda mais o 3D Vision Surround, ao permitir o uso da tecnologia com o uso de apenas uma GPU da nova geração, barateando consideravelmente o investimento necessário para se jogar em 3D com múltiplos monitores.
SLI
Antes de iniciarmos a falar da tecnologia SLI, é preciso voltar no tempo. Em 1998, em uma época em que Radeons e GeForces eram meras coadjuvantes, havia uma Rainha das Placas 3D: a Voodoo 2 da então 3Dfx. A placa tinha como destaque o suporte ao SLI (Scan Line Interleaving), que possibilitou colocar duas VGAs PCI (não confundir com o atual PCIe) Voodoo 2 para renderizar os gráficos em regime de cooperação, dividindo as linhas de varredura em pares e ímpares, sendo que cada uma das placas ficava encarregada de processar um tipo de linha. Como resultado, o ganho de performance foi imenso para a época.
Sendo assim, o objetivo da tecnologia SLI presente tanto na antiga Voodoo 2 quanto nas modernas GeForces é o mesmo: unir duas ou mais placas de vídeo em conjunto para produzir uma única saída. Trata-se, portanto, de uma aplicação de processamento paralelo para computação gráfica, destinada a aumentar o poder de processamento disponível nas placas 3D.
Depois de comprar a 3Dfx em 2001, a NVIDIA adquiriu a tecnologia, mas deixou-a “engavetada” até 2004, quando a reintroduziu com o nome de Scalable Link Interface. Contudo, a tecnologia por trás do nome SLI mudou dramaticamente.

Enquanto o modo SLI original dividia as linhas da tela (scan-lines) entre as placas — uma renderizava as linhas horizontais pares, enquanto a outra renderizava as ímpares — o modo SLI adotado pela NVIDIA (e também no CrossFire da ATI) separa o processamento por partes da tela (split frame rendering) ou em quadros alternados (alternate frame rendering). Abaixo, maiores detalhes dos métodos:
• SFR (Split Frame Rendering ou Renderização por Divisão de Quadros)
Trata-se do método em que se analisa a imagem processada a fim de dividir a carga de trabalho em duas partes iguais entre as GPUs. Para isso, o frame/quadro é dividido horizontalmente em várias proporções, dependendo da geometria. Vale destacar que o SFR não escalona a geometria ou trabalho tão bem como no AFR. Esse é o modo padrão usado pela configuração SLI usando duas placas de vídeo.
• AFR (Alternate Frame Rendering ou Renderização Alternada de Quadros)
Aqui, cada GPU renderiza frames/quadros inteiros em sequência – uma trabalhando com os frames ímpares e outra responsável pelos pares, um após o outro. Quando a placa escrava/secundária finaliza o processo de um quadro (ou parte dele), os resultados são enviados através da ponte SLI para a VGA principal, que então mostra o frame por completo. Esse é o modo utilizado normalmente pelo Tri-SLI.
• AFR de SFR
Como o próprio nome sugere, trata-se do método híbrido, no qual os dois processos descritos acima são utilizados. Dessa forma, duas GPUs processam o primeiro quadro via SFR, enquanto as outras duas renderizam o frame seguinte também em SFR. Como é possível perceber, é necessário, portanto, de quatro placas 3D, em um conjunto chamado Quad-SLI.
• SLI Antialiasing
Esse é um modo de renderização independente voltado para a melhoria da imagem, que oferece até o dobro do desempenho com o filtro antialiasing (para retirar o efeito serrilhado) ativado, através da divisão da carga de trabalho entre as duas placas de vídeo. Enquanto com uma placa é possível normalmente utilizar até 8X de filtro antialiasing, com esse método ativado pode-se chegar a 16X, 32X ou mesmo a 64X via Quad-SLI.
Assim como com o CrossFire, é preciso possuir uma placa mãe com slot PCI Express x16. Na verdade, pelo menos dois, ou ainda com três ou quatro, para Tri-SLI ou Quad-SLI. Como a comunicação entre as placas é realizada via ponte SLI (conector dedicado que ligas as VGAs) e não pelo slot PCIe, não há grandes problemas em utilizar o PCI Express na configuração x8.
Atualmente, não há restrição quando aos tipos de placas a serem utilizadas no SLI, bastando apenas que elas possuam o mesmo chip gráfico. No início, a tecnologia restringia o uso a VGAs idênticas, do mesmo fabricante e, em alguns casos, com a mesma versão da BIOS! Felizmente, hoje isso é coisa do passado.
PureVideo
 Trata-se do recurso de otimização de imagem e decodificação por hardware de vídeos nos formatos WMV, WMV-HD, MPEG4, DVD e HD-DVD, tendo ainda como vantagem o fato de desafogar a CPU do oneroso trabalho, transferindo a tarefa para a GPU. Dessa forma, o usuário poderá ainda utilizar o computador para executar outras tarefas, como por exemplo, navegar pela web.
Trata-se do recurso de otimização de imagem e decodificação por hardware de vídeos nos formatos WMV, WMV-HD, MPEG4, DVD e HD-DVD, tendo ainda como vantagem o fato de desafogar a CPU do oneroso trabalho, transferindo a tarefa para a GPU. Dessa forma, o usuário poderá ainda utilizar o computador para executar outras tarefas, como por exemplo, navegar pela web.
O PureVideo possui os seguintes recursos:
• Aceleração MPEG-2 de alta definição por hardware: Um processador dedicado de 16 vias proporciona fluência na reprodução de vídeo de alta definição (HD) com o mínimo uso da CPU;
• Aceleração WMV de Alta Definição por hardware: Suporte programável ao novo formato disponível no Windows Media Player e no Windows XP MCE 2005, proporcionando fluidez na reprodução de vídeos WMV e WMV-HD;
• Gravação de vídeos em tempo real de alta qualidade: Uma avançada engine de compensação possibilita gravação em tempo real sem perda de qualidade;
• Desentrelaçamento temporal/espacial adaptável: Permite assistir a conteúdo entrelaçado provindo de satélite, cabo e DVD nos mínimos detalhes sem serrilhados ou artefatos;
• 3:2 Correção “Pull-down” e Correção “Bad Edit”: Restaura o filme ao seu formato original de 24 fps, evitando “fantasmas” e “trepidações” durante a reprodução;
• Flicker-free Multi-Steam Scaling: Mantém a qualidade de imagem aumentando ou diminuindo a área da tela de reprodução;
• Display Gamma Correction: Detecção automática de formato que ajusta a qualidade de cor na reprodução para que não seja muito escuro ou claro demais, independentemente da tela.
Listaremos as principais tecnologias da placa de vídeo GeForce GTX 660 DirectCU II TOP.
A ASUS lançou a segunda geração das placas utilizando o sistema de cooler DirectCU II, que tem o objetivo não apenas de reduzir a temperatura da placa na comparação com sistemas de cooler referência, mas também de diminuir o ruído gerado por esses coolers.


DirectCU II

Após inúmeras tentativas para alcançar o projeto de refrigeração ideal, surgiu a Série de Coolers DirectCU, desenvolvida pelos engenheiros térmicos da empresa. Os coolers da série possuem design exclusivo, no qual tubos de calor são aplicados diretamento no core da GPU para a dissipação mais rápida do ar quente. Como o calor é retirado mais rápido, os fans podem operar a uma velocidade mais baixa, gerando menos ruído.

Gpu Tweak

O utilitário permite aos usuários ajustar a velocidade de clock e a performance da ventoinha, trabalhando com até quatro placas – perfeita para configurações SLI. Proporcionando diferentes experiências de uso com os modos ‘padrão’ e ‘avançado’, os ajustes no GPU Tweak permitem alterar a voltagem da GPU, o que oferece um potencial de overclock ainda maior. O utilitário pode atualizar o driver e o BIOS da placa automaticamente, mantendo o sistema em condições ideais de funcionamento. Para monitorar o estado do sistema diretamente da área de trabalho, o GPU Tweak oferece também um prático widget.

DIGI+ VRM e Super Alloy Power
 A tecnologia DIGI+ VRM está presente também nas placas-mãe da ASUS, e é aplicada através de um design de energia de seis fases que utiliza reguladores de voltagem para minimizar o desperdício de energia por 30%, aperfeiçoar a eficiência em 15%, aumentar a tolerância de modulagem de voltagem e melhorar estabilidade e longevidade geral em até 2,5 vezes sobre a referência.
A tecnologia DIGI+ VRM está presente também nas placas-mãe da ASUS, e é aplicada através de um design de energia de seis fases que utiliza reguladores de voltagem para minimizar o desperdício de energia por 30%, aperfeiçoar a eficiência em 15%, aumentar a tolerância de modulagem de voltagem e melhorar estabilidade e longevidade geral em até 2,5 vezes sobre a referência.

Estabilidade em overclock 30% maior
DIGI+ VRM, ao contrário de um design análogo tradicional, conta com configurações digitais para ajustar a voltagem de acordo com diferentes cenários de overclock. Graças à mudança precisa de voltagem, leva a menor desperdício de energia, de 239 mV a 159 mV.

Maior eficiência de energia em 15%
DIGI+ VRM transfere inteligentemente a corrente por fases, resultando em menor perda de energia. O design de controle de energia eficientemente leva o consumo de energia dos 34,4 W originais para 28,7 W.

50% menos EMI
A tecnologia dinamicamente ajusta frequências, o que resulta em uma queda de EMI para 20 decibéis, dos originais 40 decibéis.


A nova tecnologia Super Alloy Power nas placas gráficas da ASUS utiliza uma fórmula especial de liga que possui alta magnetividade, resistência ao calor e qualidade anticorrosiva. Ela consegue uma performance mais estável e silenciosa que o design padrão.

O Super Alloy Capacitor (Capacitador de Super Liga) aumenta o tempo de vida da placa para 150 mil horas, o que é 2,5 vezes mais do que um capacitador normal.
Componentes Super Alloy são reforçados com uma formula de liga especial e manufaturados sob altas temperaturas e pressão para atingir uma operação mais estável e livre de ruídos. Mais informações sobre essa tecnologia em placas de vídeo, e outros componentes que a utilizam, foram reunidas neste pequeno artigo.
A GeForce GTX 660 DirectCU II TOP está entre as melhores placas com chip Geforce GTX 660, nas fotos abaixo podemos ver que em se tratando de acabamento ela segue o padrão de alta qualidade da ASUS e da linha DirectCU II, composta por modelos diferenciados. Reparem que a ASUS agora embala a placa envolta a um plastico mantendo ela bem presa internamente, evitando assim ficar “correndo” dentro da caixa e causar possíveis problemas. Em se tratando de acessórios, nada se não um conector DVI>D-Sub e DVD com drivers.
Como já demonstramos, o sistema de cooler merece destaque especial, por ser um projeto bastante diferenciado, possibilitando que a placa vá muito além do que um modelo referencia em situações extremas como de overclock. Entre seus destaque podemos citar os três heatpipes e dois FANs do cooler. Assim como a referência ela vem com um conector PCI-Express de 6 pinos.


Reparem também que a placa possui apenas um conector SLI, possibilitando dual SLI, diferente da 660Ti que possui dois conectores e dessa forma suporta 4 placas trabalhando em conjunto.
Como de constume, utilizamos uma máquina TOP de linha baseada em um processador Intel Core i7 3960X overclockado para 4.6GHz.
Abaixo, fotos do sistema montado com a ASUS GeForce GTX 660 DirectCU II TOP.
A seguir, os detalhes da máquina, sistema operacional, drivers, configurações de drivers e softwares/games utilizados nos testes.
Máquina utilizada nos testes:
– Mainboard MSI Big Bang XPower II
– Processador Intel Core i7 3960X @ 4.6GHz
– Memórias 16 GB DDR3-1600MHz Corsair Dominator-GT
– HD 1TB Sata2 Western Digital Black
– Fonte XFX ProSeries 1000W
– Cooler Thermaltake Water 2.0 Pro
Sistema Operacional e Drivers:
– Windows 7 64 Bits
– Intel INF 9.3.0.1020
– Catalyst 12.6 WHQL: Placas AMD
– GeForce 296.10 WHQL: Placas Nvidia GeForce 500
– GeForce 301.10 WHQL: Placas Nvidia GeForce 600
– GeForce 305.37 BETA – GTX 660Ti
– GeForce 306.23 BETA – GTX 660
Configurações de Drivers:
3DMark
– Anisotropic filtering: OFF
– Antialiasing – mode: OFF
– Vertical sync: OFF
– Demais opções em Default
Games:
– Anisotropic filtering: Variado através do game testado
– Antialiasing – mode: Variado através do game testado
– Texture filtering: High-Quality
– Vertical sync: OFF
– Demais opções em Default
Aplicativos/Games:
– 3DMark 11 1.0.3 (DX11)
– Unigine HEAVEN Benchmark 3.0 (DX11)
– Aliens vs Predator (DX11)
– Batman Arkham City (DX11)
– Crysis Warhead (DX10)
– Crysis 2 (DX11)
– DiRT 3 (DX11)
– Just Cause 2 (DX10.1)
– Mafia II (DX9)
– Metro 2033 (DX11)
– Sniper Elite V2 Benchmark (DX11)
Abaixo temos a tela principal do GPU-Z, mostrando algumas das principais características técnicas da GTX 660 DirectCU II TOP da ASUS, que possui clock do core superior ao modelo referência que tem clock do GPU em 980MHz. Já as memórias desse modelo trabalha 100MHz acima do padrão, com clock em 6108MHz.

GPU Boost
Antes dos testes, vejam um vídeo que fizemos demonstrando a tecnologia GPU Boost em ação rodando com uma GTX 680 referência, reparem na mudança constante do clock e voltagem da placa.

Temperatura
Iniciamos nossa bateria de testes com um bench bastante importante: a temperatura do chip, tanto em modo ocioso como em uso contínuo.
Em modo ocioso (idle), a GTX 660 DirectCU II da ASUS consegue um bom desempenho, mas fica um pouco atrás de outros modelos, inclusive de uma 660 Ti da MSI. Vale destacar que no caso da 660 DirectCU II o overclock feito é mais agressivo e exigindo mais do GPU, consequentemente aquecendo mais.
Medimos o pico de temperatura durante os testes do 3DMark 11 rodando em modo contínuo. A placa consegue novamente bom resultado, ficando na segunda posição da tabela entre as placas que menos aquecem, mostrando a eficiência do sistema de cooler DirectCU II.
Também fizemos testes de consumo de energia com todas as placas comparadas. Os testes foram feitos todos em cima da máquina utilizada na review, o que da a noção exata do que cada VGA consome.
Em modo ocioso (também conhecido como idle), o consumo de energia da ASUS GeForce GTX 660 DirectCU II TOP é bom, mas devido seu alto overclock da fábrica, a coloca pouco atrás da 670.
No teste de carga, rodando o 3DMark 11, e aumentando o consumo de energia das placas colocando-as em situações de maior demanda de potência, a placa conseguiu bom resultado, ficando na segunda posição na tabela.
OBS.: No teste em modo ocioso consideramos 5w como margem de erro. Já no teste rodando o aplicativo 3DMark 11 consideramos 15w como margem de erro, devido grande variação que acontece testando a mesma placa.

Com o 3DMark 11, versão mais recente do aplicativo para testes de desempenho de placas de vídeo mais famoso do mundo, a GTX 660 DirectCU II TOP consegue bom desempenho, apenas 1% abaixo da HD 7870. A performance no entanto fica bem inferior à 660 Ti, cerca de 21% abaixo.
Unigine HEAVEN 3.0 – DirectX 11

Trata-se de um dos testes sintéticos mais “descolados” do momento, pois tem como objetivo mensurar a capacidade das placas 3D em suportar os principais recursos da API gráfica DirectX 11, como é o caso do Tessellation.
O teste foi dividido em duas partes: uma sem e outra com o uso do Tessellation, ambas a 1920×1080 com o filtro de antialiasing em 8x e anisotropic em 16X.
No primeiro teste, com o tessellation desativado, a placa já volta a se aproximar da 660 Ti, apenas 4% abaixo da “irmã mais velha”, e ficando 1% acima da HD 7850. No entando, ela vê a HD 7870 abrir vantagem, com superioridade de quase 18%.
Usando o tessellation ativado em modo normal, as posições não se alteraram, a GTX 660 apenas viu a 660 Ti e a HD 7870 abrirem um pouco mais a vantagem.

Começamos os testes em jogos com o Aliens vs Predator, game que traz o suporte ao DX11 e que foi muito bem recebido pelo público e crítica.
Em AvP, a ASUS GeForce GTX 660 DirectCU II TOP se aproxima da GTX 660 Ti, ficando com desempenho apenas 2% abaixo na resolução mais leve e com um empate técnico na mais alta, e aumenta superioridade em relação à HD 7850 para 8%. A HD 7870 continua a uma distância considerável, no entanto: 10% acima.

O FPS futurístico da Crytek fez muito barulho por trazer uma qualidade gráfica bem superior a dos concorrentes e por ser considerado por muito tempo como um dos games que mais exigia recursos do computador, principalmente das placas 3D. Assim, nada melhor do que submeter as VGAs da review pelo crivo de “Crysis Warhead”.
Neste teste, a GTX 660 da ASUS consegue desempenho superior ao da HD 7870, mesmo que por menos de 2%. Mesmo assim, vê novamente a GTX 660 Ti se distanciar, abrindo cerca de 9,5%.

Para os testes com o Crysis 2, utilizamos a ferramenta Adrenaline Crysis 2 Benchmark Tool, que lançamos no ano passado e é utilizada por praticamente todos os websites internacionais para benchmarks com o Crysis 2. O game, como todos sabem, é referência em qualidade de imagem, e no mês de junho 2011 finalmente ganhou seu patch com suporte ao DirectX 11, já que originalmente o game vinha apenas em DX9.
A placa é ultrapassada novamente pela HD 7870, que apresenta desempenho cerca de 2% superior. A 660 Ti mantém a vantagem na casa dos 9%. A HD 7850, no entanto, ainda fica bem abaixo.

DiRT 3 é o game mais recente de uma das séries de corrida off-road de maior sucesso da história da indústria dos jogos eletrônicos. Lançado em junho de 2011, o game traz o que existe de melhor em tecnologia da API DirectX 11. Os testes com o game foram feitos utilizando a ferramenta Adrenaline Racing Benchmark Tool.
Neste game vemos uma boa vantagem para os modelos da NVIDIA, que povoam o topo da lista. O desempenho da GTX 660 é tão bom que ela consegue um empate técnico com a HD 7950, não ficando mais de 2% abaixo da rival. Assim, ela deixa a HD 7870 com quase 8% de inferioridade na resolução mais alta. No entanto, a GTX 660 Ti consegue um desempenho ainda maior, mais de 17%.

Para fazer o “contra peso”, as placas da série Radeon dominam em todos os segmentos rodando o Just Cause 2, curiosamente apoiado pela NVIDIA.
Neste game, a GTX 660 segue a tendência de todas as placas com GPU NVIDIA e vê os chips da AMD apresentando grande melhora. Assim, a placa da ASUS é superada até pela HD 7850, com performance cerca de 4% inferior.

Mafia II trouxe a continuação do aclamado game de ação em terceira pessoa ambientado no obscuro mundo da máfia italiana dos anos 40 e 50, nos EUA.
A GTX 660 mantém um padrão médio obtido até aqui, carca de 8% abaixo da HD 7870 e 10 % acima da HD 7850. A principal diferença aqui é a vantagem da GTX 660 Ti, que consegue uma superioridade de quase 20%.

Trata-se de um FPS da 4A Games baseado em um romance homônimo russo, que conta a saga dos sobreviventes de uma guerra nuclear ocorrida em 2013 que se refugiam nas estações de metrô. O game, que faz uso intensivo da técnica de Tessellation e demais recursos do DirectX 11, desbancou de Crysis o título de jogo mais pesado. Sendo assim, nada melhor do que observar como se comportam as VGAs sob este intenso teste.
Com o game, a placa fica empatada com a HD 7850, já que pela diferença que existe em apenas uma resolução pode ser considerada empate técnico entre os modelos. Já a diferença para a HD 7870 existe e fica na casa de 15%. Pelo menos a diferença para a GTX 660 Ti cai para 10%.
Quando se trata de uma placa de vídeo da Nvidia, não temos como não testar a tecnologia de física PhysX, presente em alguns games e que promete maior realismo, adicionando efeitos não encontrados em placas que não sejam da empresa.
Para os testes, utilizamos o Batman Arkham City, sequência da série que traz efeitos muito bons dessa tecnologia. Abaixo, um exemplo da diferença do game rodando com e sem PhysX.

Como a tecnologia adiciona mais efeitos, ela exige mais da placa de vídeo e consequentemente afeta diretamente o desempenho. Abaixo, nos testes com a tecnologia ativada, temos um desempenho muito bom da placa, conseguindo um empate com a GTX 580 Lightning Xtreme, placa high-end overclockada da geração passada. Não é suficiente para se aproximar muito da GTX 660 Ti, mas é um bom resultado.
Assim como sua irma maior a GTX 660 não tem potencial de overclock tão alto, ficando entre 10 e 20% no máximo em se tratando do clock normal. O GPU Boost vai atuar aumentando um pouco mais o clock da placa. Esse modelo tem entre seus principais diferenciais ser um projeto diferenciado a fim de tornar a placa uma das melhores com o chip GTX 660. Conseguimos coloca-la com o core trabalhando estável em 1140MHz, aumento de 16% sobre o clock referência. As memórias subimos para 6600MHz, 600MHz acima da referência e 500MHz acima do clock original desse modelo.
Confiram abaixo uma imagem com o aplicativo AUS GPU Tweak e a tela principal do GPU-Z mostrando o overclock feito.

Temperatura
Incrivelmente, a placa não apresentou aumento nenhum de temperatura quando overclockada.
Consumo de Energia
Aumento de apenas nove Watts, insuficiente até para chegar perto do consumo da HD 7870. O acréscimo é muito pequeno. A 660 Ti quando overclockada, por exemplo, apresenta crescimento de 17 Watts.
3DMark 11
O overclock trouxe um ganho de performance na casa dos 4%, no teste com o 3DMark. Assim, a placa conseguiu superar o desempenho da HD 7870 e se aproximar ao da HD 7950, ficando com 2% de diferença entre as duas.
Além do 3DMark 11, fizemos testes com a placa overclockada na resolução de 1920×1080 em alguns games. Vamos acompanhar abaixo como a placa se comportou.
Aliens vs Predator
A GTX 660 exibe um comportamento bem semelhante ao da sua “irmã mais velha”, a GTX 660 Ti. Assim, também consegue um aumento de desempenho de pouco mais de 7% e mantém a diferença entre ambas overclockadas semelhante à de ambas com clock base. O aumento de velocidade serve para diminuir a inferioridade em relação à HD 7870 para menos de 3%.
Crysis 2
O crescimento de 5,25% não é suficiente para ultrapassar a performance da GTX 660 Ti em clock base, mas a deixa com resultados 3,51% melhores que os da HD 7870.
Metro 2033
Aumento de desempenho de pouco menos de 6%, suficiente para ultrapassar HD 7870 e HD 6970. No entanto, não é o bastante para alcançar a GTX 660 Ti em clock base, que ainda matém uma vantagem de quase 7%.
A Asus GTX 660 DirectCU II TOP nos surpreendeu positivamente pelo fato de entregar um sólido nível de desempenho para a categoria. Conforme evidenciado em nossos testes, a placa chegou em muitos casos a ter uma performance bem próxima à GTX 580, GeForce top da geração anterior. Se comparada com a sua rival direta – a Radeon HD 7870 – a GTX 660 mostrou ser uma concorrente a altura, tanto em termos de desempenho, quanto de preço.
Por falar em valor, o modelo da Asus é apenas US$ 20 mais caro que o modelo de referência (US$ 229). Trata-se de um patamar bem interessante, se levarmos em conta todos os diferencias da placa – como clocks turbinados, cooler diferencial e componentes reforçados – bem como pelos FPS a mais, tornando a VGA ainda mais “sedutora”.

Outros destaques da GeForce GTX 660 referem-se a suavidade (uso dos filtros FXAA/TXAA e do Adptive VSync) e maior riqueza (3D Vision Surround com apenas 1 VGA/GPU, e PhysX mais poderoso).
Por fim, a mudança na arquitetura da Kepler além de proporcionar uma maior otimização na relação desempenho por watt gasto, permitiu uma estratégia de marketing bastante interessante para a companhia: a de possuir VGAs com quantidades de Shaders Processors (ou Stream Processors / CUDA Cores) bem próximas as Radeons rivais. Nada de discrepância da ordem de 2,5-3 vezes.
A Asus GTX 660 DirectCU II TOP nos surpreendeu positivamente pelo fato de entregar um sólido nível de desempenho para a categoria. Com design arrojado, cooler eficiente e componentes de alta qualidade, a placa é sem dúvidas, uma forte candidata a estar no gabinete dos gamemaníados.
{galeria::Asus_GeForce_GTX_660_DirectCU_II_TOP,ASUS GeForce GTX 660 DirectCU II TOP}
- Categorias

Participe do grupo de ofertas do Adrenaline
Confira as principais ofertas de hardware, componentes e outros eletrônicos que encontramos pela internet. Placa de vídeo, placa-mãe, memória RAM e tudo que você precisa para montar o seu PC. Ao participar do nosso grupo, você recebe promoções diariamente e tem acesso antecipado a cupons de desconto.
Entre no grupo e aproveite as promoções










